For this activity, we classify the same set of objects as with activities 18 and 19 but using neural networks instead. A neural network will have three parts, the input layer, the hidden layer and the output layer. For classification purposes, the input layer contains the features and the output would contain the classes. As with activity 19 I used piatos and pillows as my 2 classes. The output may either be 0 (piatos) or 1 (pillows) depending on which class a sample belongs.
The code below follows the one written by Jeric. I used 4 input layer neurons, 8 hidden layer neurons and 1 output layer neuron. The following is the code I used, the training and test sets are the ones in activity 19.
-----------------------------------------------------------------------------------
chdir("C:\Users\RAFAEL JACULBIA\Documents\subjects\186\activity20");
N = [4,8,1];
train = fscanfMat("train.txt")';// Training Set
t = [0 0 0 0 1 1 1 1];
lp = [2.5,0];
W = ann_FF_init(N);
T = 500; //Training cyles
W = ann_FF_Std_online(train,t,N,W,lp,T);
test = fscanfMat("test2.txt")';
class = ann_FF_run(test,N,W)
round(class)
--------------------------------------------------------------------------
The following are the outputs of the program :
0.0723331 0.0343279 0.0358914 0.0102084 0.9948734 0.9865080 0.9895211 0.9913624
After rounding off, we see that the above outputs are 100% accurate.
I grade myself 10/10 for again getting a perfect classification. Thanks to jeric for the code and to ed for his help.
Thursday, October 9, 2008
Thursday, October 2, 2008
Activity 19: Probabilistic Classification
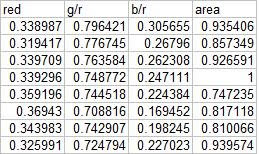
In this activity, we again classify different objects like what we did in activity 18. Only this time we perform linear discrimination analysis. It mainly assumes that our classes are separable by a linear combination of different features of the class. Class membership is attained for when a certain sample has minimum error of classification. A detailed discussion is given in Linear_Discrimant_Analysis_2.pdf by Dr. Sheila Marcos. The samples I used for this activity are piatos(class 1) and pillows (class 2). The features I used are: normalized area obtained via pixel counting, average value of the red component, ratio of the average value of the green component to the red component, and the ratio of the average value of the blue component to the red component. These parameters are obtained using the procedure described in my earlier post for activity 18. The first four samples are used as training set and the last four are used as the test set.
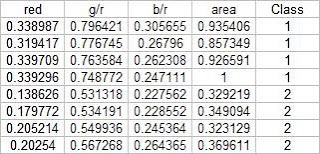
Using the above training set and the methods described in the provided pdf file, we can compute for the covariance matrix given below:
The test set is given below:
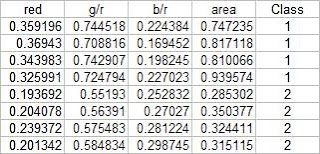
From this test set, the computed discrimant values are:
 From these result it is obvious that I was able to obtain a 100% correct classification. I also tried this with a different sample combination (pillows vs squidballs) and I still got 100% correct classification. The following is the code I used:
From these result it is obvious that I was able to obtain a 100% correct classification. I also tried this with a different sample combination (pillows vs squidballs) and I still got 100% correct classification. The following is the code I used:
-----------------------------------------------------------------------
chdir("C:\Users\RAFAEL JACULBIA\Documents\subjects\186\activity19");
x = [];
y = [];
x1 = [];
x2 = [];
u1 = [];
u2 = [];
x1o = [];
x2o = [];
c1 = [];
c2 = [];
C = [];
n = 8;
n1 = 4;
n2 = 4;
x = fscanfMat("x.txt");
y = fscanfMat("y.txt");
test = fscanfMat("test.txt");
x1 = x(1:n1,:);
x2 = x(n1+1:n,:);
u1 = mean(x1,'r');
u2 = mean(x2,'r');
u = mean(x,'r');
x1o(:,1) = x1(:,1) - u(:,1);
x1o(:,2) = x1(:,2) - u(:,2);
x1o(:,3) = x1(:,3) - u(:,3);
x1o(:,4) = x1(:,4) - u(:,4);
x2o(:,1) = x2(:,1) - u(:,1);
x2o(:,2) = x2(:,2) - u(:,2);
x2o(:,3) = x2(:,3) - u(:,3);
x2o(:,4) = x2(:,4) - u(:,4);
c1 = (x1o'*x1o)/n1;
c2 = (x2o'*x2o)/n2;
C = (n1/n)*c1 + (n2/n)*c2;
p = [n1/n;n2/n];
class = [];
for i = 1:size(test,1)
f1(i) = u1*inv(C)*test(i,:)'-0.5*u1*inv(C)*u1'+log(p(1));
f2(i) = u2*inv(C)*test(i,:)'-0.5*u2*inv(C)*u2'+log(p(2));
end
f1-f2
------------------------------------------------------------------------
I proudly grade myself 10/10 for getting it perfectly without the help of others. I also consider this activity one of the easiest because of the step by step method given in the provided file.

Using the above training set and the methods described in the provided pdf file, we can compute for the covariance matrix given below:
0.0062310 0.0087568 0.0012735 0.0226916
0.0087568 0.0129916 0.0019430 0.0329768
0.0012735 0.0019430 0.0005591 0.0042263
0.0226916 0.0329768 0.0042263 0.0876073
The test set is given below:

From this test set, the computed discrimant values are:
 From these result it is obvious that I was able to obtain a 100% correct classification. I also tried this with a different sample combination (pillows vs squidballs) and I still got 100% correct classification. The following is the code I used:
From these result it is obvious that I was able to obtain a 100% correct classification. I also tried this with a different sample combination (pillows vs squidballs) and I still got 100% correct classification. The following is the code I used:-----------------------------------------------------------------------
chdir("C:\Users\RAFAEL JACULBIA\Documents\subjects\186\activity19");
x = [];
y = [];
x1 = [];
x2 = [];
u1 = [];
u2 = [];
x1o = [];
x2o = [];
c1 = [];
c2 = [];
C = [];
n = 8;
n1 = 4;
n2 = 4;
x = fscanfMat("x.txt");
y = fscanfMat("y.txt");
test = fscanfMat("test.txt");
x1 = x(1:n1,:);
x2 = x(n1+1:n,:);
u1 = mean(x1,'r');
u2 = mean(x2,'r');
u = mean(x,'r');
x1o(:,1) = x1(:,1) - u(:,1);
x1o(:,2) = x1(:,2) - u(:,2);
x1o(:,3) = x1(:,3) - u(:,3);
x1o(:,4) = x1(:,4) - u(:,4);
x2o(:,1) = x2(:,1) - u(:,1);
x2o(:,2) = x2(:,2) - u(:,2);
x2o(:,3) = x2(:,3) - u(:,3);
x2o(:,4) = x2(:,4) - u(:,4);
c1 = (x1o'*x1o)/n1;
c2 = (x2o'*x2o)/n2;
C = (n1/n)*c1 + (n2/n)*c2;
p = [n1/n;n2/n];
class = [];
for i = 1:size(test,1)
f1(i) = u1*inv(C)*test(i,:)'-0.5*u1*inv(C)*u1'+log(p(1));
f2(i) = u2*inv(C)*test(i,:)'-0.5*u2*inv(C)*u2'+log(p(2));
end
f1-f2
------------------------------------------------------------------------
I proudly grade myself 10/10 for getting it perfectly without the help of others. I also consider this activity one of the easiest because of the step by step method given in the provided file.
Activity 18: Pattern Recognition
In this activity we are to identify to what class an object belongs to. We do this by extracting relevant features about different samples of the object and comparing its features to a training set. The criteria for membership in a certain class is when its features has a minimum distance to a certain class' representative features obtained by getting the mean of each features of the samples from each class. The classes I used are piatos chips, pillow chocolate filled snack, kwek kwek and squidballs. The images of the objects are shown below:

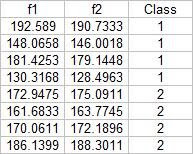
I chose four features that can be extracted from the objects; normalized area obtained via pixel counting, average value of the red component, ratio of the average value of the green component to the red component, and the ratio of the average value of the blue component to the red component. Since we have only eight samples I used the first four as a training set and the tested the class membership of the training set. The mean feature vectors are shown below:
Class membership is obtained by taking the minimum distance between a test's feature to the mean of each feature, following the formula given by Dr. Soriano's pdf file:
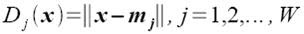
Using the features and the above formula, I obtained 15 correct classifications out of 16 samples translating to a 93.75% correct classification.
For the extraction of the parameters of the samples, I performed parametric color image segmentation we learned from activity 16. Afterwards, I inverted the segmented image, performed the morphological closing operation and multiplied it to the original colored image to obtain a colored segmented image. I used excel to perform the minimum distance classification, it was tedious but I understand it better if I do it this way :0. The scilab code I used for the extraction of the parameters is shown below:
For this activity I grade myself 10/10 since I was able to get a relatively high correct classification percentage.
Ed David helped me a lot in this activity. Special thanks to Cole, JM, Billy, Mer, Benj for buying the samples for this activity.

I chose four features that can be extracted from the objects; normalized area obtained via pixel counting, average value of the red component, ratio of the average value of the green component to the red component, and the ratio of the average value of the blue component to the red component. Since we have only eight samples I used the first four as a training set and the tested the class membership of the training set. The mean feature vectors are shown below:

Class membership is obtained by taking the minimum distance between a test's feature to the mean of each feature, following the formula given by Dr. Soriano's pdf file:

Using the features and the above formula, I obtained 15 correct classifications out of 16 samples translating to a 93.75% correct classification.
For the extraction of the parameters of the samples, I performed parametric color image segmentation we learned from activity 16. Afterwards, I inverted the segmented image, performed the morphological closing operation and multiplied it to the original colored image to obtain a colored segmented image. I used excel to perform the minimum distance classification, it was tedious but I understand it better if I do it this way :0. The scilab code I used for the extraction of the parameters is shown below:
For this activity I grade myself 10/10 since I was able to get a relatively high correct classification percentage.
Ed David helped me a lot in this activity. Special thanks to Cole, JM, Billy, Mer, Benj for buying the samples for this activity.
Tuesday, September 16, 2008
Activity 17: Basic Video Processing
In this activity, we are to analyze a video clip. The video clip we will analyze is a simple kinematic experiment and we are to extract certain physical parameters of the experiment and confirm the results analytically. To analyze the video, we need to separate its frames then on this frames we can apply the image processing techniques we have learned so far in the course. The experiment we designed is a simple rolling disk on an inclined plane. An animated gif of the set of images is shown below (video was cropped before images were extracted).

Our goal is to extract the acceleration of the object along the incline. First, we need to segregate the region of interest (ROI) from the background. From our previous lessons, we have two choices of image segmentation, color and binary. Since the video does not really contain important color information, I chose to perform binary image segmentation. The crucial step in this method is the choice of the threshold value. For this activity I found that a threshold value of 0.6 produced good results. However, the a good segmentation was still not achieved since the reflection of light in some parts of the image caused the color of the ramp to be unequal. A gif image of the result after thresholding is shown below:

Clearly, this is not what we want so I performed opening operation using a 10x5 structuring element both to further segregate the ROI from the background of the image and to make the edges of the ROI smooth. The resulting set of images is shown below:

Now we can track the position of the ROI in time. The position over time in pixels can be obtained from the average value of the x pixel position per image. Distance per unit time where distance is in pixels and time is in frames. The conversion factor we obtained is 2mm/pixel and from the video the frame rate is 24.5fps. After conversion I was able to obtain 0.5428m/sec^2.
Analytically, from Tipler, the acceleration along an inclined plane of a hollow cylinder is given by a = (g*sin(theta))/2, where theta is the angle of the incline, for our case theta = 6degrees. Using the formula we get 0.5121m/sec^2. This translates to roughly 5.66% of error. The scilab code I used is given below:
------------------------------------------------------------------------------
chdir("C:\Users\RAFAEL JACULBIA\Documents\subjects\186\activity17\hollow");
I = [];
x = [];
y = [];
vs=[];
ys = [];
xs = [];
as=[];
se = ones(10,5);
se2 = im2bw(se2,0.5);
for i = 6:31
I = imread("hollow" + string(i-1) + ".jpg");
I = im2bw(I,0.6);
I = dilate(erode(I,se),se);
imwrite(I , string(i)+ ".png" );
I = imread( string(i) + ".png");
[x,y] = find(I==1);
xs(i) = mean(x);
ys(i) = mean(y);
end
ys = ys*2*10**(-3);
vs = (ys(2:25)-ys(1:24))*24.5;
as = (vs(2:24)-vs(1:23))*24.5;
-------------------------------------------------------------
I grade myself 9/10 for this activity for not getting a fairly high error percentage.
Collaborators:
Ed David
JM Presto

Our goal is to extract the acceleration of the object along the incline. First, we need to segregate the region of interest (ROI) from the background. From our previous lessons, we have two choices of image segmentation, color and binary. Since the video does not really contain important color information, I chose to perform binary image segmentation. The crucial step in this method is the choice of the threshold value. For this activity I found that a threshold value of 0.6 produced good results. However, the a good segmentation was still not achieved since the reflection of light in some parts of the image caused the color of the ramp to be unequal. A gif image of the result after thresholding is shown below:

Clearly, this is not what we want so I performed opening operation using a 10x5 structuring element both to further segregate the ROI from the background of the image and to make the edges of the ROI smooth. The resulting set of images is shown below:

Now we can track the position of the ROI in time. The position over time in pixels can be obtained from the average value of the x pixel position per image. Distance per unit time where distance is in pixels and time is in frames. The conversion factor we obtained is 2mm/pixel and from the video the frame rate is 24.5fps. After conversion I was able to obtain 0.5428m/sec^2.
Analytically, from Tipler, the acceleration along an inclined plane of a hollow cylinder is given by a = (g*sin(theta))/2, where theta is the angle of the incline, for our case theta = 6degrees. Using the formula we get 0.5121m/sec^2. This translates to roughly 5.66% of error. The scilab code I used is given below:
------------------------------------------------------------------------------
chdir("C:\Users\RAFAEL JACULBIA\Documents\subjects\186\activity17\hollow");
I = [];
x = [];
y = [];
vs=[];
ys = [];
xs = [];
as=[];
se = ones(10,5);
se2 = im2bw(se2,0.5);
for i = 6:31
I = imread("hollow" + string(i-1) + ".jpg");
I = im2bw(I,0.6);
I = dilate(erode(I,se),se);
imwrite(I , string(i)+ ".png" );
I = imread( string(i) + ".png");
[x,y] = find(I==1);
xs(i) = mean(x);
ys(i) = mean(y);
end
ys = ys*2*10**(-3);
vs = (ys(2:25)-ys(1:24))*24.5;
as = (vs(2:24)-vs(1:23))*24.5;
-------------------------------------------------------------
I grade myself 9/10 for this activity for not getting a fairly high error percentage.
Collaborators:
Ed David
JM Presto
Tuesday, September 2, 2008
Activity 16: Color Image Segmentation
The objective of this activity is to "segment" or select a region of interest from an image according to its color. To do this, we have to transform the RGB space into normalized chromaticity coordinates (NCC). We do this obtaining this by dividing each pixel by the sum of the RGB values in that pixel. Afterwards, the chromaticity can easily be represented by two color channels r and g since b = 1-r+g. The image used and the test image is shown below:
OBJECT

TEST IMAGE

Two methods are used in this activity, non-parametric and parametric. Parametric segmentation is done by determining the probability that a region belongs to the region of interest. In particular, a gaussian probability distribution function is assumed. For non-parametric segmentation, the frequency value of the pixel in the histogram itself is used to backproject the value for that pixel. The two dimensional histogram of the original image test image is shown below:
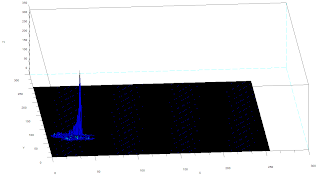 The x-axis corresponds to the R channel, the y-axis corresponds to the G channel and the z axis corresponds to the frequency. From the figure, it can be seen that the region where the frequency is highest is at the blue region as expected.
The x-axis corresponds to the R channel, the y-axis corresponds to the G channel and the z axis corresponds to the frequency. From the figure, it can be seen that the region where the frequency is highest is at the blue region as expected.
The following are the results of the color segmentation:
 It can be seen from the images that parametric segmentation looks better as it was able to approximate the general shape of the blue parts of the lamp are well separated from the other colors. However, the non-parametric segmentation is very accurate in the sense that slight changes in the shade of blue in the image is no longer considered blue. This is easily observed in the post of the lamp since in this part the shade is darker than the top parts.
It can be seen from the images that parametric segmentation looks better as it was able to approximate the general shape of the blue parts of the lamp are well separated from the other colors. However, the non-parametric segmentation is very accurate in the sense that slight changes in the shade of blue in the image is no longer considered blue. This is easily observed in the post of the lamp since in this part the shade is darker than the top parts.
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
Scilab Codes:
Parametric
I = imread("lamp_section.jpg");
orig = imread("lamp_orig.jpg");
av = I(:,:,1)+I(:,:,2)+I(:,:,3);
r = I(:,:,1)./av;
g = I(:,:,2)./av;
b = I(:,:,3)./av;
av2 = orig(:,:,1)+orig(:,:,2)+orig(:,:,3);
r2 = orig(:,:,1)./av2;
g2 = orig(:,:,2)./av2;
b2 = orig(:,:,3)./av2;
r = r*255;
g = g*255;
frequency = zeros(256,256);
sizer = size(r);
for i=1:sizer(1)
for j=1:sizer(2)
x = abs(round(r(i,j)))+1;
y = abs(round(g(i,j)))+1;
frequency(x,y) = frequency(x,y)+1;
end
end
//imshow(log(frequency+0.0000000001));
r = r/255;
g = r/255;
mr = mean(r);
devr = stdev(r);
mg = mean(g);
devg = stdev(g);
pr = (1/(devr*sqrt(2*%pi)))*exp(-((r2-mr).^2)/2*devr);
pg = (1/(devg*sqrt(2*%pi)))*exp(-((g2-mg).^2)/2*devg);
prob = pr.*pg;
prob = prob/max(prob);
scf(0);imshow(orig);
scf(1);imshow(prob,[]);
-------------------------------------------------------------------------------------------------
Non Parametric:
I = imread("lamp_section.jpg");
orig = imread("lamp_orig.jpg");
sizeO = size(orig)
av = I(:,:,1)+I(:,:,2)+I(:,:,3);
r = I(:,:,1)./av;
g = I(:,:,2)./av;
b = I(:,:,3)./av;
av2 = orig(:,:,1)+orig(:,:,2)+orig(:,:,3);
r2 = orig(:,:,1)./av2;
g2 = orig(:,:,2)./av2;
b2 = orig(:,:,3)./av2;
r = r*255;
g = g*255;
frequency = zeros(256,256);
sizer = size(r);
for i=1:sizer(1)
for j=1:sizer(2)
x = abs(round(r(i,j)))+1;
y = round(g(i,j))+1;
frequency(x,y) = frequency(x,y)+1;
end
end
scf(0);imshow(log(frequency+0.0000000001));
r2 = r2*255;
g2 = g2*255;
seg = zeros(sizeO(1),sizeO(2));
sizer2 = size(r2);
for i = 1:sizer2(1)
for j = 1:sizer2(2)
x = abs(round(r2(i,j)))+1;
y = round(g2(i,j))+1;
seg(i,j) = frequency(x,y);
end
end
scf(1);imshow(log(seg+0.000000000001),[]);
scf(2);imshow(orig);
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
I will give myself a grade of 10 for this activity since the objectives were met and the results are interesting.
Collaborator:
Ed David


OBJECT

TEST IMAGE

 The x-axis corresponds to the R channel, the y-axis corresponds to the G channel and the z axis corresponds to the frequency. From the figure, it can be seen that the region where the frequency is highest is at the blue region as expected.
The x-axis corresponds to the R channel, the y-axis corresponds to the G channel and the z axis corresponds to the frequency. From the figure, it can be seen that the region where the frequency is highest is at the blue region as expected. The following are the results of the color segmentation:
 It can be seen from the images that parametric segmentation looks better as it was able to approximate the general shape of the blue parts of the lamp are well separated from the other colors. However, the non-parametric segmentation is very accurate in the sense that slight changes in the shade of blue in the image is no longer considered blue. This is easily observed in the post of the lamp since in this part the shade is darker than the top parts.
It can be seen from the images that parametric segmentation looks better as it was able to approximate the general shape of the blue parts of the lamp are well separated from the other colors. However, the non-parametric segmentation is very accurate in the sense that slight changes in the shade of blue in the image is no longer considered blue. This is easily observed in the post of the lamp since in this part the shade is darker than the top parts.----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------
Scilab Codes:
Parametric
I = imread("lamp_section.jpg");
orig = imread("lamp_orig.jpg");
av = I(:,:,1)+I(:,:,2)+I(:,:,3);
r = I(:,:,1)./av;
g = I(:,:,2)./av;
b = I(:,:,3)./av;
av2 = orig(:,:,1)+orig(:,:,2)+orig(:,:,3);
r2 = orig(:,:,1)./av2;
g2 = orig(:,:,2)./av2;
b2 = orig(:,:,3)./av2;
r = r*255;
g = g*255;
frequency = zeros(256,256);
sizer = size(r);
for i=1:sizer(1)
for j=1:sizer(2)
x = abs(round(r(i,j)))+1;
y = abs(round(g(i,j)))+1;
frequency(x,y) = frequency(x,y)+1;
end
end
//imshow(log(frequency+0.0000000001));
r = r/255;
g = r/255;
mr = mean(r);
devr = stdev(r);
mg = mean(g);
devg = stdev(g);
pr = (1/(devr*sqrt(2*%pi)))*exp(-((r2-mr).^2)/2*devr);
pg = (1/(devg*sqrt(2*%pi)))*exp(-((g2-mg).^2)/2*devg);
prob = pr.*pg;
prob = prob/max(prob);
scf(0);imshow(orig);
scf(1);imshow(prob,[]);
-------------------------------------------------------------------------------------------------
Non Parametric:
I = imread("lamp_section.jpg");
orig = imread("lamp_orig.jpg");
sizeO = size(orig)
av = I(:,:,1)+I(:,:,2)+I(:,:,3);
r = I(:,:,1)./av;
g = I(:,:,2)./av;
b = I(:,:,3)./av;
av2 = orig(:,:,1)+orig(:,:,2)+orig(:,:,3);
r2 = orig(:,:,1)./av2;
g2 = orig(:,:,2)./av2;
b2 = orig(:,:,3)./av2;
r = r*255;
g = g*255;
frequency = zeros(256,256);
sizer = size(r);
for i=1:sizer(1)
for j=1:sizer(2)
x = abs(round(r(i,j)))+1;
y = round(g(i,j))+1;
frequency(x,y) = frequency(x,y)+1;
end
end
scf(0);imshow(log(frequency+0.0000000001));
r2 = r2*255;
g2 = g2*255;
seg = zeros(sizeO(1),sizeO(2));
sizer2 = size(r2);
for i = 1:sizer2(1)
for j = 1:sizer2(2)
x = abs(round(r2(i,j)))+1;
y = round(g2(i,j))+1;
seg(i,j) = frequency(x,y);
end
end
scf(1);imshow(log(seg+0.000000000001),[]);
scf(2);imshow(orig);
-------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------
I will give myself a grade of 10 for this activity since the objectives were met and the results are interesting.
Collaborator:
Ed David
Wednesday, August 27, 2008
Activity 15: Color Image Processing
For this activity, we are to perform 2 different white balancing techniques, called the reference white algorithm and the gray world algorithm. In the reference white algorithm, a reference white object's pixel values are to be used to normalize the red, green and blue channels of the whole image. On the other hand, gray world algorithm uses the mean of each of the RGB channel values as the normalization factor.
We used two sets of objects for this activity. One set is a set of objects with different colors and another set is a set of objects with the same colors. For my second set I used a blue set of objects. The images were taken under a fluorescent lamp using the "tungsten", "daylight" and "cloudy" white balancing settings of a Canon Powershot A460 digital camera.
The following are the results for object with different colors:
 TUNGSTEN
TUNGSTEN
 CLOUDY
CLOUDY
 DAYLIGHT
DAYLIGHT
For all the images, Reference white algorithm seems to work better since the gray world algorithm requires a certain constant to be multiplied to reduce the brightness of the resulting image. For this part the constant used to limit the brightness is 0.75.
The following are the results for different blue objects under different white balancing conditions.
 CLOUDY
CLOUDY
 DAYLIGHT
DAYLIGHT
 TUNGSTEN
TUNGSTEN
We used two sets of objects for this activity. One set is a set of objects with different colors and another set is a set of objects with the same colors. For my second set I used a blue set of objects. The images were taken under a fluorescent lamp using the "tungsten", "daylight" and "cloudy" white balancing settings of a Canon Powershot A460 digital camera.
The following are the results for object with different colors:
 TUNGSTEN
TUNGSTEN CLOUDY
CLOUDY DAYLIGHT
DAYLIGHTFor all the images, Reference white algorithm seems to work better since the gray world algorithm requires a certain constant to be multiplied to reduce the brightness of the resulting image. For this part the constant used to limit the brightness is 0.75.
The following are the results for different blue objects under different white balancing conditions.
 CLOUDY
CLOUDY DAYLIGHT
DAYLIGHT TUNGSTEN
TUNGSTENFor images with the same color, the reference white algorithm clearly performs better. The results of the gray world algorithm produced images with slightly redder image. A possible reason is because an average of an ensemble of colors may become white but an ensemble of objects having similar colors is not necessarily white. Hence, the white reference algorithm is expected to perform better.
Scilab Code:
I = imread("IMG_0921_cloudy.jpg");
//start of reference white algorithm
imshow(I);
pos = locate(1);
Rw = I(pos(1),pos(2),1);
Gw = I(pos(1),pos(2),2);
Bw = I(pos(1),pos(2),3);
//Start of gray world algorithm
//Rw = mean(I(:,:,1));
//Gw = mean(I(:,:,2));
//Bw = mean(I(:,:,3));
I(:,:,1) = I(:,:,1)/Rw;
I(:,:,2) = I(:,:,2)/Gw;
I(:,:,3) = I(:,:,3)/Bw;
//I = I*0.5;
I(I>1) = 1;
imwrite(I,"enhanced_cloudy.jpg");
----------------------------------------------
10/10 for this activity since I was able to finish the activity quickly and correctly.
Collaborator: Eduardo David
Scilab Code:
I = imread("IMG_0921_cloudy.jpg");
//start of reference white algorithm
imshow(I);
pos = locate(1);
Rw = I(pos(1),pos(2),1);
Gw = I(pos(1),pos(2),2);
Bw = I(pos(1),pos(2),3);
//Start of gray world algorithm
//Rw = mean(I(:,:,1));
//Gw = mean(I(:,:,2));
//Bw = mean(I(:,:,3));
I(:,:,1) = I(:,:,1)/Rw;
I(:,:,2) = I(:,:,2)/Gw;
I(:,:,3) = I(:,:,3)/Bw;
//I = I*0.5;
I(I>1) = 1;
imwrite(I,"enhanced_cloudy.jpg");
----------------------------------------------
10/10 for this activity since I was able to finish the activity quickly and correctly.
Collaborator: Eduardo David
Subscribe to:
Posts (Atom)